

Problem Statement
Large Language Models like GPT-4, Llama, and Mistral are remarkable but this powerful models comes at a cost. A single model can take up 10 to 100 GB of memory, making them expensive to run and nearly impossible to deploy and use on personal devices like laptops or smartphones and on edge.
Model Size : They can be hundreds of GBs
Hardware Requirements: Inference often needs expensive GPUs.
Latency: Running a single prompt can take seconds, even minutes.
Energy Cost: High-performance inference burns a lot of compute.
What if we could put these giant models on a diet, shrinking or reducing them down without making them lose their "brain power"?
The Solution: Quantization
Quantization is a smart compression trick that lets you shrink and speed up models without breaking their intelligence.

Lets begin with Analogy
Imagine you have a high-resolution image. The file is huge because it stores an every tiny amount of color detail for each pixel. Now, imagine converting that photo to a JPEG format. The image still looks great and fine to our human eyes, but the file size is drastically smaller. How? To save space, the JPEG format creates a simpler version of an image using a smaller color palette. This new version is a "good enough" that looks almost identical but is much smaller in size. Quantization is a “JPEG compression” for AI models.
Quantization isn’t a new idea invented for LLMs. It's an existing fundamental concept in digital technology.
For example, In digital audio, A sound wave is a smooth, continuous (analog) signal. To create an MP3 file, that smooth wave is measured at thousands of points per second. Each measurement is break to the nearest value on a predefined scale.
 - Wikipedia")
This process of converting a continuous signal into a set of discrete steps is quantization. It's how we fit an entire symphony into a small digital file.
Compression & Floating Point Numbers
To understand quantization, we need to first understand compression and the role of floating points in general.
“Compression” is the method of making these models smaller and so it faster, without significantly hurting their performance. Just like how we zip files to save space, model compression reduces size and speeds up inference, so that making it easier to run AI models on edge devices, mobiles, or with limited hardware like in local computers.
In the world of machine learning and deep learning, models often grow large and complex packed with millions (or even billions) of parameters. Any LLM or Deep learning model's “knowledge” is stored in a massive network layers of numbers called weights and biases. Think of these as millions of tiny adjustment knobs that the model learned to tune and accurate during its training.

Typically, these numbers are stored in a highly precise format called 32-bit floating point (FP32). Most machine learning models use floating-point numbers to represent weights and activations. These are numbers with decimals (like 0.0012 or 3.1415), and they’re ideal for capturing the tiny changes that happen during training.
3Blue1Brown gave a visual and intuitive explanation of “what is neural networks”
Since Model training involves a lot of mathematical operations like multiplying inputs with weights and adjusting those weights slowly and focus on high precision to make sure the learning is accurate and stable.
These are often stored in 32 bits, meaning each number takes up 32 binary digits in memory.

The Problem with full precision is 32-bit for every single weight and activation can blow up the memory.
For example: 7B model can take ~ 28 GB of memory. Inference becomes slow and power-hungry.
What if the same models stores using only 8 bits instead ?
That’s just 1/4th the memory per number! Of course, with fewer bits, we lose some precision but in many cases, especially during inference (when the model is just making predictions), you don’t need super high precision to get good results.
Quantization converts these high-precision FP32 numbers into a lower-precision format, like 8-bit integers. This means less memory, faster computation, and often minimal loss in accuracy.
Lets take an Input : 3.1415
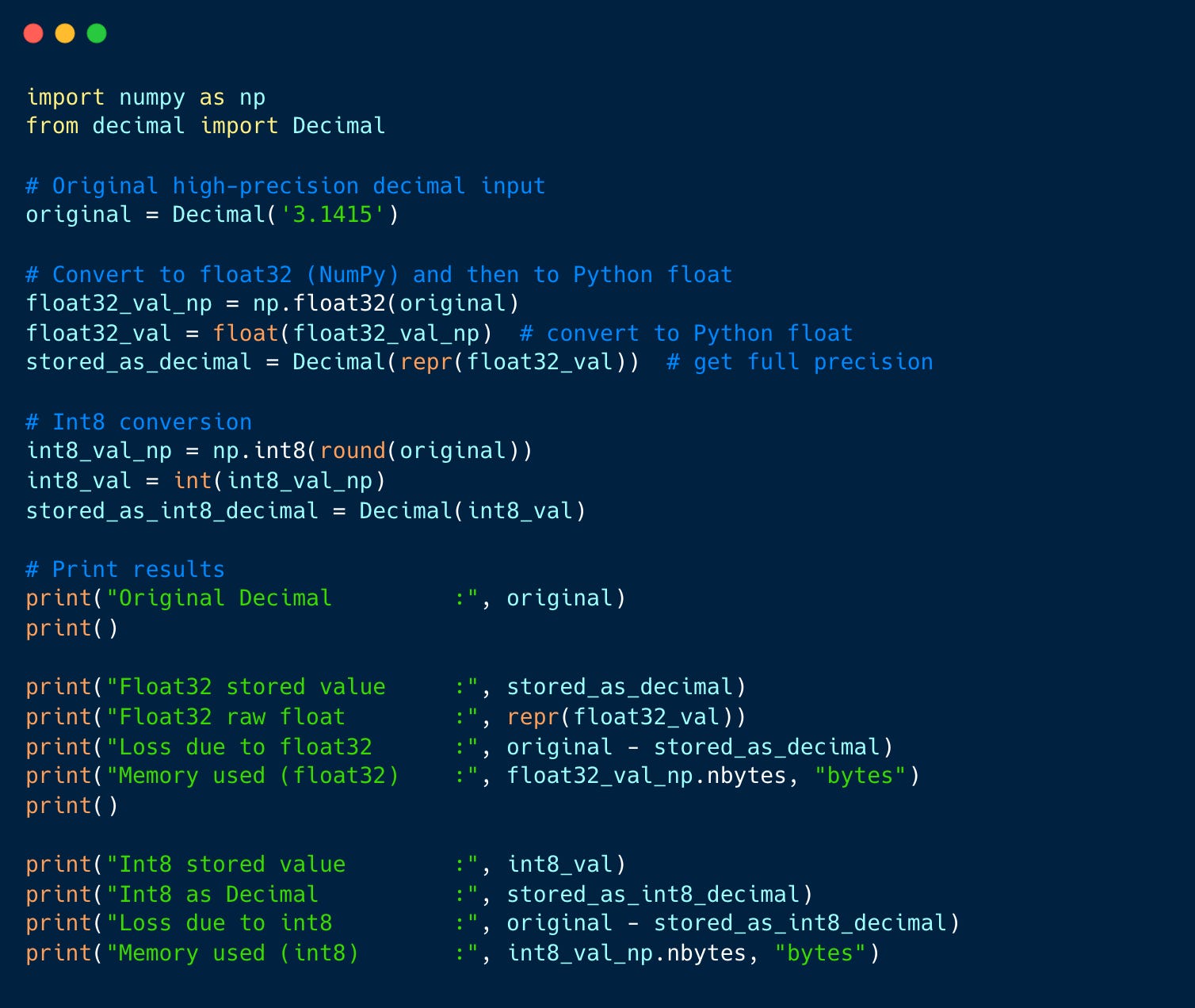
Result:
Original Decimal : 3.1415
Float32 stored value : 3.1414999961853027
Float32 raw float : 3.1414999961853027
Loss due to float32 : 3.8146973E-9
Memory used (float32) : 4 bytes
Int8 stored value : 3
Int8 as Decimal : 3
Loss due to int8 : 0.1415
Memory used (int8) : 1 bytesWhen we convert 3.1415 to float32, it uses 4 bytes and keeps the value almost the same, with only a tiny loss in precision. But when we convert it to int8, it uses just 1 byte and loses the decimal part, leading to a bigger difference.
This shows that using less memory can mean losing some accuracy.
Types of Quantization: Choosing Your Strategy
The right approach of Quantization depends on the goals we want to achieve, whether we prioritizing model accuracy or reducing the size.
The main strategies fall into two major categories:
when you quantize
what you quantize.
Category 1: When to Quantize
1. Post-Training Quantization (PTQ)
This is the most popular and straightforward approach. The name itself explains, take a fully trained, high-precision model and convert its weights after all the training is done.

It doesn’t require retraining or access to the original training dataset.
It’s the method used by popular tools like bitsandbytes.
💡 It’s like taking a finished, high-resolution photograph and using a tool like Photoshop to save it as a smaller JPEG. The original work is already complete; you're just performing a final conversion step.
📌 Since model wasn’t trained with quantization in mind, converting its precision can sometimes lead to a drop in performance, especially with very aggressive quantization (like 4-bit or lower).
2. Quantization-Aware Training (QAT)
This is a more advanced and powerful technique. Instead of quantizing at the end, you simulate the effects of quantization during the training or fine-tuning process. The model learns to adapt to the lower precision from the start.
QAT almost always results in better performance than PTQ because the model has learned to compensate for the precision loss.
It requires access to a representative training dataset and involves a full fine-tuning or training cycle, which is computationally expensive.
Category 2: What to Quantize
3. Weight-Only Quantization
This is the most common technique for shrinking large language models. Here, we only quantize the model's weights, the static parameters that store its knowledge. The activations (the data that flows through the model during a calculation) are kept in a higher-precision format like FP16.
Drastically reduce memory footprint (RAM/VRAM).
📌 Why do this? The weights make up the majority of an LLM's size. Quantizing them gives high reduction in memory and storage.
Below code example is based on this technique. The load_in_4bit flag in transformers uses weight-only quantization.
4. Weight and Activation Quantization
For maximum performance, you can quantize both the weights and the activations. The core mathematical operations of the model (like matrix multiplications) can be performed entirely using integer instead of FP32.
Integer calculations are significantly faster on most modern CPUs and GPUs than floating-point calculations.
This provides a speed inference.
This technique is very common for models running on edge devices like smartphones.
Quantization Libraries & Code Walkthrough
Now that We’ve covered the concepts and methods. In Part 2, we’ll explore any one of the popular quantization libraries like bitsandbytes, llama.cpp, and Hugging Face's transformers, and walk through actual code examples.
Recommended Readings
A Visual Guide to Quantization by Maarten Grootendorst

Nice one Kannan. I’m sure enterprises are already applying quantisation to solve problems like, reduced computing and mass adoption instead of purely relying on general purpose model.