


Artifacts #5
The Egg Puff Engineer's Newsletter

Hello Reader 👋
Welcome to the 5th Issue Newsletter. This issue focus topic segments and a new micro-learning format, making it easier to explore, learn, and dive deeper.
🚀 3 Things in AI
News | Concepts | Insights
🌊 News
1️⃣ Jules.Google - Google has launched Jules, an autonomous AI coding agent now in public beta, designed to assist developers by performing tasks such as writing tests, fixing bugs, and updating dependencies. Operating asynchronously within a secure Google Cloud virtual machine, Jules integrates directly with existing repositories and offers features like audio changelogs and GitHub integration.
Personal Take: I tried building a couple of features and fixing some bugs in my personal project. The results were solid, with clear plans provided upfront for review and approval. The task limit was increased from 6 to 60. I’m having trouble cloning the proposed code changes and testing them outside the console before pushing the PR. Occasionally, the UI unexpectedly auto-approves the plan before I even click.

2️⃣ Google’s Stitch

AI-powered design tool from Google Labs that transforms text prompts and images into functional UI designs and frontend code within minutes. Leveraging the multimodal capabilities of Gemini 2.5 Pro, Stitch enables users to generate interfaces from natural language descriptions or visual inputs like sketches and wireframes. Stitch aims to streamline the collaboration between designers and developers, making the app creation process more efficient and accessible.
3️⃣ Open-source humanoid robots - Hugging Face has unveiled two open-source humanoid robots: HopeJR and Reachy Mini. Both robots are fully open-source, allowing developers to build, modify, and customize them. These developments are supported by Hugging Face's LeRobot platform, which offers models, datasets, and tools for real-world robotics in PyTorch.
🧠 Concept : Understanding Embeddings in LLMs
Follow-up from last week: "What are tokens & parameters in AI models?" If you haven’t checked it out yet, take a look. it adds useful background for today’s topic.
Embeddings in Simple Terms?
Imagine words are people trying to attend a party. The problem is, the security system at the door only understands numbers, not text. So, to let them in, each word needs a special numerical ID that carries meaning about who they are. That’s what embeddings do: they turn words (or sentences, or data) into numerical representations called vectors (lists of numbers) that capture their meaning and context in a high-dimensional space.
Technically Speaking...
For example, words like "refund" and "money back" would be placed close together in this numerical space, while unrelated words like "laptop" would be farther away.
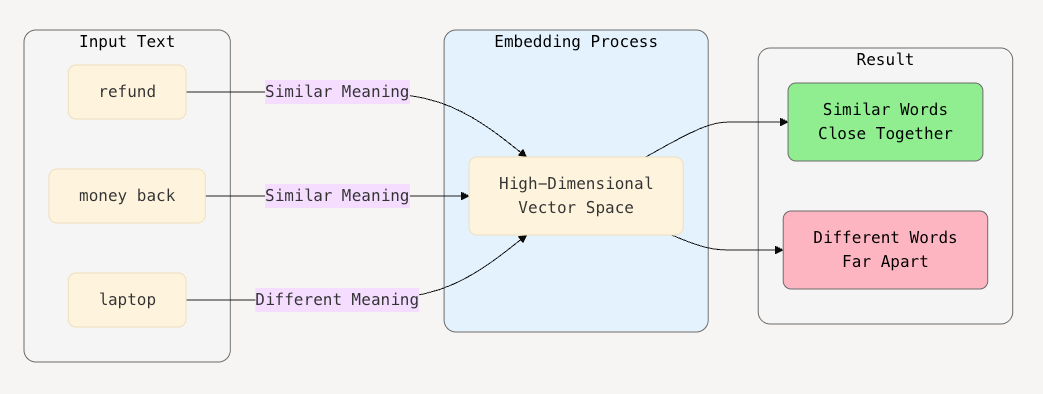
An embedding is a dense vector of numbers (e.g., [0.12, -0.98, 0.53, ...]) representing a word or a piece of text in a high-dimensional space (like 768 or 1536 dimensions in real models).
The numbers like 768 or 1536 refer to the dimensionality of the embedding vectors. basically, how many numbers are used to represent a word, sentence, or input. These aren't random; they're architecture-specific choices made when designing language models. If a model has 768-dimensional embeddings, that means each token is represented as a vector of 768 numbers.

Because real-world language is complex and nuanced. A single number or 2D coordinate isn’t enough to capture the relationships. In embedding space, these relationships become geometric patterns.
Embedding Vectors (Example)
Let’s take the word "money" and “refund”, and the model gives this embedding in 768-dimensional vector.
# example values
"money" → [0.32, -0.19, 0.87, ..., 0.05]
"refund" → [0.30, -0.20, 0.85, ..., 0.06]Notice they're numerically close, which means the model understands that these words are semantically similar.
Why Embeddings Matter in LLMs and Where They Fit in the Workflow
Without embeddings, LLMs would only see arbitrary word IDs (like "apple" = 1021, "banana" = 573), no context or similarity. There would be no way to capture relationships, meaning, or intent.
Right after Tokenization, and before Transformer processing.

Pre-trained Embedding Models
Why Do We Need Pre-Trained Embedding Models?
Because training embeddings from scratch is hard, slow, and requires a lot of data but language understanding is universal, so we can reuse it. When we use a pre-trained embedding model, we're using a map of language that someone already built by reading millions of documents.

Embeddings Used in
Semantic Search: Find similar documents or questions
Recommendations: Match users to products based on text
Clustering: Group similar content
LLM Memory: For retrieval-augmented generation (RAG)
Additional Reads : https://huggingface.co/spaces/hesamation/primer-llm-embedding
📊 Insights : The Pedagogy Benchmark
AI models do well at student exams, but do we know about pedagogy and helping students learn? The Pedagogy Benchmark to see if models can pass teacher exams. Top 15 ( Commercial + Open Source )

🔦 Explore This
Sharing some open-source projects this week that can power your AI systems.
1. LanceDB
LanceDB is an open-source vector database for AI that's designed to store, manage, query and retrieve embeddings on large-scale multi-modal data. The core of LanceDB is written in Rust 🦀 and is built on top of Lance, an open-source columnar data format designed for performant ML workloads and fast random access.
2. Dotprompt
Dotprompt is an executable prompt template file format for Generative AI. It is designed to be agnostic to programming language and model provider to allow for maximum flexibility in usage. Dotprompt extends the popular Handlebars templating language with GenAI-specific features.

🧩 Engineers Placeholder

Skyplane is a tool for blazingly fast bulk data transfers between object stores in the cloud. It provisions a fleet of VMs in the cloud to transfer data in parallel while using compression and bandwidth tiering to reduce cost.
https://skyplane.org/en/latest/
Hope you found something useful this week. Feel free to share your feedback !
Until next time,
Egg Puff Engineer