
Fail-Safe Patterns for AI Agent Workflows
Lessons from distributed systems applied to the next generation of AI.

For AI agents and any complex AI systems to be effective in the real world, they need be more than just intelligence; they need to be resilient. They must be able to withstand unexpected issues and continue to function when things go wrong. Because inevitably, things will go wrong like LLM Models sometimes hallucinate, LLM API services time out, data formats change unexpectedly, or external tools become unavailable.
That’s why we need "fail-safe" approaches. These are like backup plans that help the system keep working, even if not perfectly, instead of just crashing completely.
For multi-AI agent systems, these fail-safes aren't just a nice feature; they're absolutely essential to keep the agents performing their tasks reliably and cohesively.
In this post, I’ll break down:
What fail-safe patterns are ?
Why they’re critical in distributed AI/agent systems ?
A practical example of implementing fail-safes in an AI agent pipeline.
Bonus : A Fail-Safe Refund Agent Implementation
What is a Fail-Safe Pattern?
Remember the movie Fail-Safe (1964)? A glitch in a U.S. military system accidentally sends nuclear bombers toward the Soviet Union, and the entire plot becomes a race to prevent global catastrophe. Fail-safe patterns in software serve the same purpose; stopping small failures before they spiral out of control.

A fail-safe pattern is an architectural strategy that prevents the failure of a single component from cascading and collapsing the entire system. Its goal is not just to avoid failures but to handle them safely, minimizing harm to users, protecting other components, and preserving the overall system’s stability.
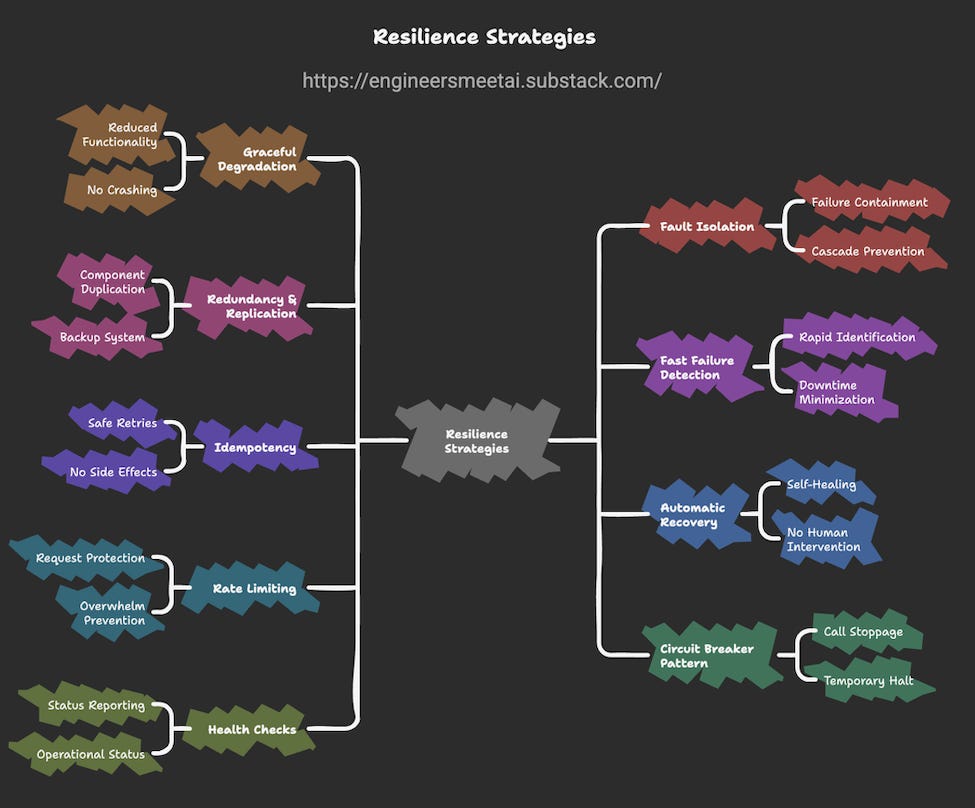
Why Fail-Safes Matter in AI Agents
Most AI agent pipelines usually look like this.
Pull data from multiple sources like LLMs, APIs, and vector databases.
Orchestrate workflows across distributed pipelines such as planners, RAG, and toolchains.
Interact with the real world including IoT devices, robots, and external systems.
This complex orchestration makes AI system, so powerful but also fragile. A single issue, such as a model API timing out, can freeze the whole system. In this situation, With the right resilience strategies , we can turn fragile AI Agent into robust AI Agent.
For example:
Retry intelligently instead of giving up on the first error.
Use cached results when live data is not available.
Reroute tasks around the failure point.
Return partial but useful results instead of nothing.
Here are some of the scenarios where fail-safe patterns can protect your system:
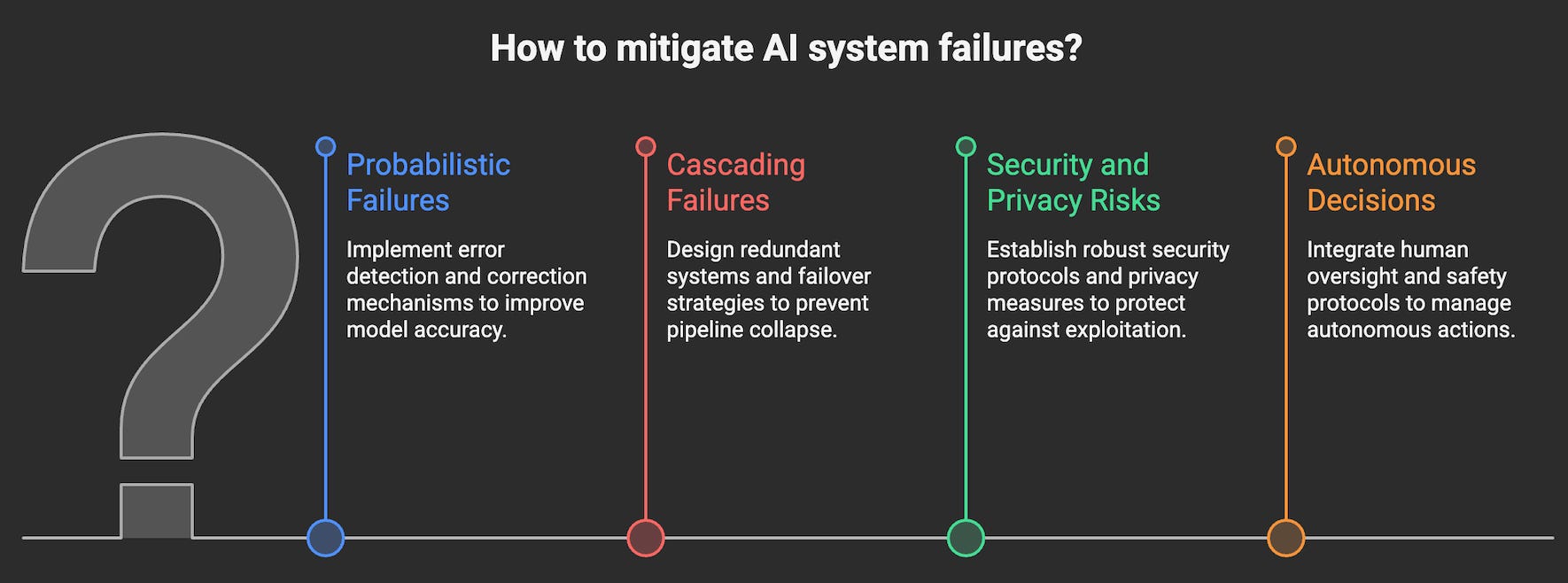
1. Probabilistic Failures
AI models do not always produce the same output for the same input, and even when they do, the result may still be wrong. This is because they work on probabilities. For example:
A retrieval system might return irrelevant documents because of a slightly ambiguous query.
A model might hallucinate facts or generate an incorrect plan.
An agent might misinterpret incomplete data and take the wrong action.
Fail-safes here could include confidence thresholds, result validation steps, or fallback rules that trigger a safe default action.
2. Cascading Failures
AI pipelines often have many dependencies, and one broken link can bring everything to a halt. Examples:
If your data ingestion pipeline fails, downstream models may receive empty or outdated inputs.
A task planner that fails to produce a plan could block every tool in the workflow from executing.
If a single API dependency times out, the whole workflow may on hold.
Fail-safes here could involve retries with backoff, graceful degradation (skipping non-critical steps), or routing to backup or alternative services to keep the system running.
3. Security and Privacy Risks
AI systems can be attacked or unintentionally leak sensitive information. For instance:
Prompt injection attacks can trick an LLM into exposing confidential data or performing unintended actions.
Data poisoning can corrupt training data and cause incorrect outputs.
Fail-safes can include sanitizing inputs, restricting model access, monitoring outputs for sensitive data, and using encryption or access control to protect data.
4. Autonomous Decisions Gone Wrong
Agents often operate without constant human supervision. This means they can make harmful or costly decisions if left unchecked. Examples:
A robot moving into an unsafe area because of a sensor error.
An AI assistant taking irreversible actions (deleting data, sending emails) based on misinterpreted instructions.
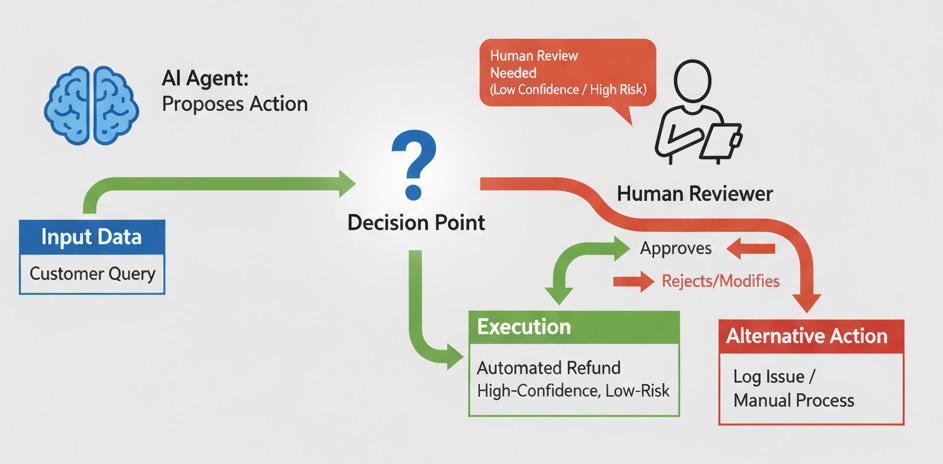
Fail-safes can include human-in-the-loop approvals for critical actions, kill switches to stop unsafe behavior, and simulation or sandbox testing before deployment.
Fail-Safe Patterns in Action
Here are three patterns commonly used:
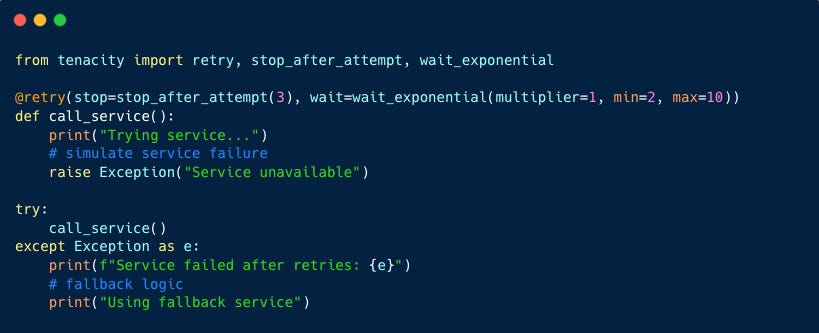
1. Timeout + Retry with Backoff
If an LLM API call or a data retrieval times out, the agent retries with exponential backoff rather than retrying endlessly.
Exponential backoff is a smart retry strategy where the system waits a little longer each time before trying again, instead of retrying immediately or endlessly.

For example: 1st retry wait 100ms, 2nd retry wait 200ms and so on..
This pattern keeps doubling the wait time until either the request succeeds or the system stops trying after a maximum number of attempts.
Fail-safe behavior: Instead of crashing, the agent returns a default response after retries.
In the below example, I have used tenacity is a popular Python library for retrying functions with exponential backoff
2. Fallback Models
When your primary LLM provider (e.g., GPT-4 API) is unavailable or times out, route the request to a secondary, smaller, or local model. This ensures your system continues to function, even if with reduced quality or slower responses.
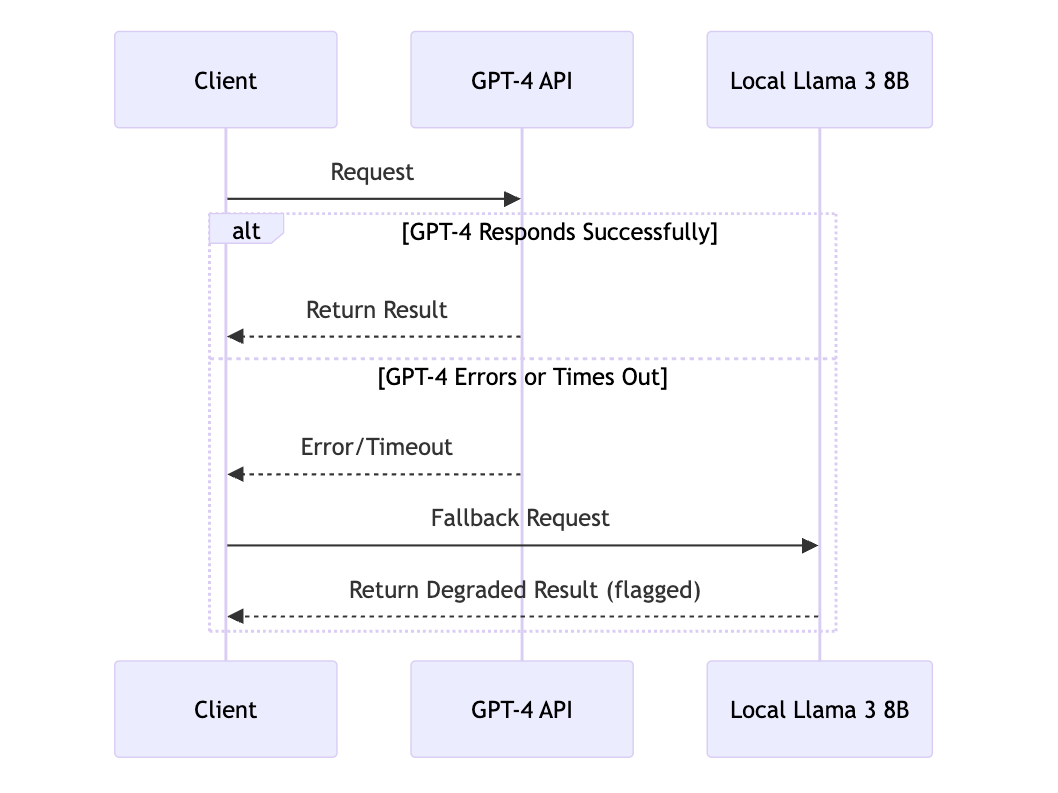
Fail-safe behavior: Users get a slightly less accurate answer instead of no answer.
3. Circuit Breaker Pattern
The Circuit Breaker Pattern prevents repeatedly calling a failing service (eg., GPT-4 API Service) when it is likely to stay down for a while. Instead of hammering the API and wasting resources, it “opens the circuit” and quickly fails or switches to an alternative (like a cached result or local model).
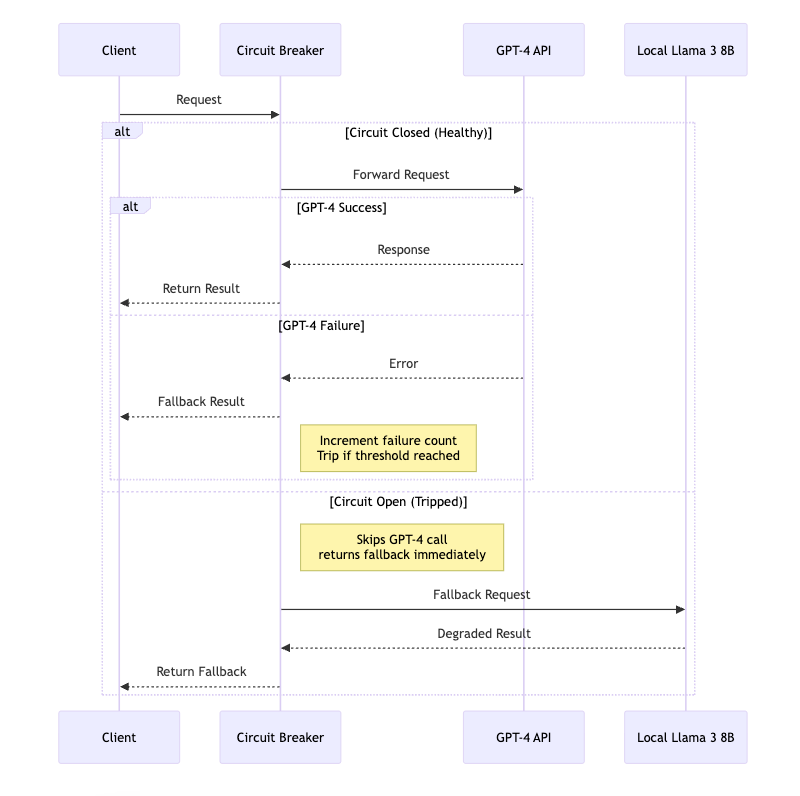
Fail-safe behavior: Rather than hitting a failing service over and over, the system protects itself and switches to a fallback.
In this example, I have used open source library pybreaker - Python implementation of the Circuit Breaker pattern
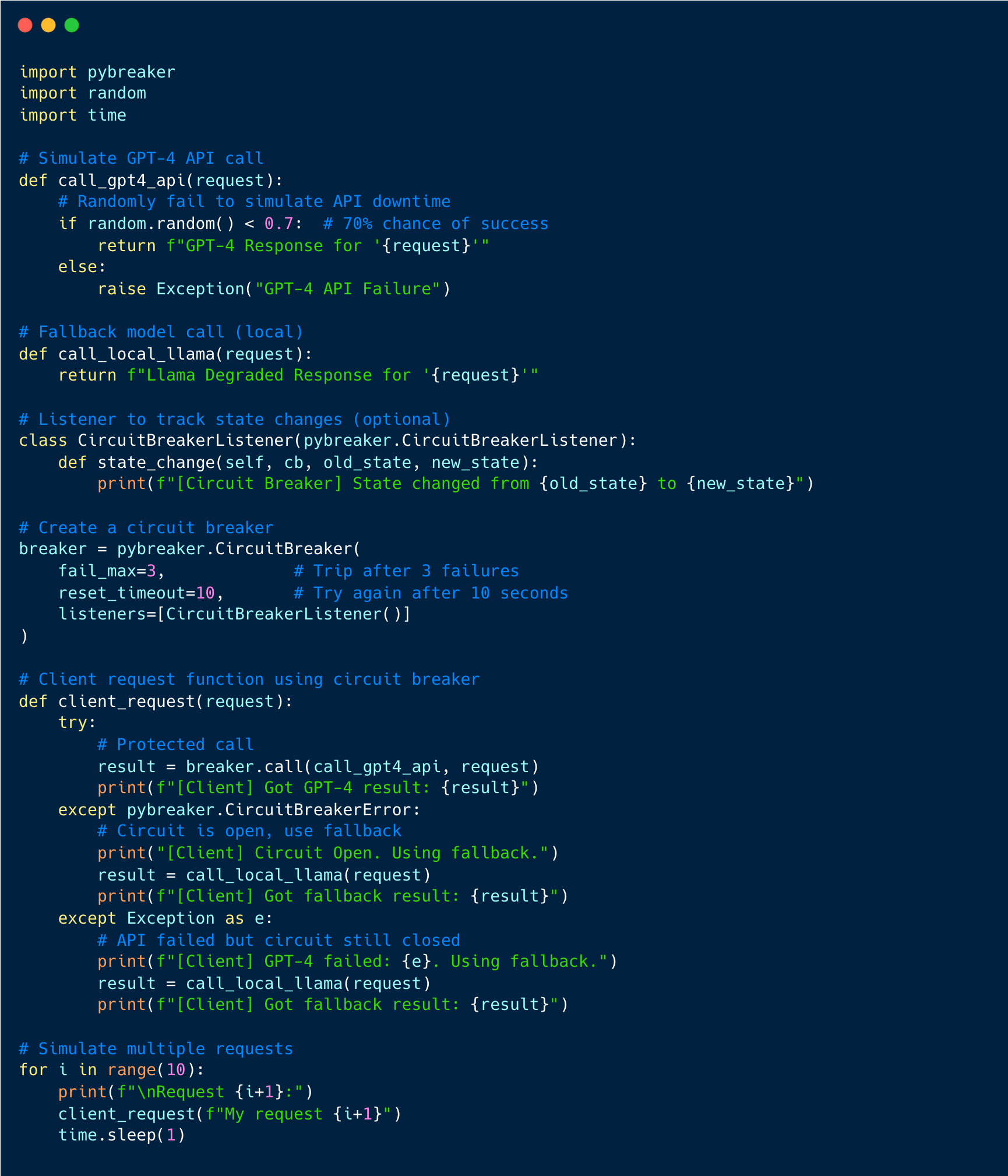
breaker.call()wraps the GPT-4 API call.If GPT-4 fails repeatedly (>=3 times), the circuit opens.
While the circuit is open,
pybreaker.CircuitBreakerErroris raised immediately.Fallback (
Llama) is called if GPT-4 fails or circuit is open.Circuit resets after
reset_timeoutseconds to retry GPT-4.
🤖 AI runs on compute. I run on coffee. Fuel the next post if you enjoyed this one!
Bonus: A Fail-Safe Refund Agent
I built a simple version of LangChain-based Refund Agent that applies these fail-safe patterns that could be part of automated customer support workflow. The agent can process refunds safely while coordinating with external services and gracefully handling failures.
You can find implementation code in the when-engineers-meet-ai GitHub repo.
https://github.com/kannandreams/when-engineers-meet-ai/tree/main/code/fail-safe-patterns
I have learned four things about fail safe ,
- Exponential retries is an important mechanism
- Backup models are saviours
- Circuit breaker patterns
- Fourth I used my own fingers to type this entire comment , its fail safe because I didnt rely on gpt for this :D :D: D