
How Distributed Inference Actually Works
Understanding Exo, RDMA, and Distributed Inference on Apple Silicon

I’ve been experimenting with local models recently, particularly Qwen3 Coder running through MLX on Apple Silicon. My current setup looks like this:
Development Machine
MacBook Pro M5 Pro - 48 GB Unified Memory
Qwen3 Coder running via MLX
VS Code + Continue Extension as the primary development environment
Secondary Machine
Mac Mini M1
16 GB Unified Memory
Ollama serving chat-focused Gemma4 models
While local AI has been exciting to explore, it hasn't been without challenges like context limits, VS Code integrations, repeated looping in responses and tokens per second, etc.
RDMA, EXO and Distributed Inference
Recently, I got introduced about Exo from my favourite Substack newsletter Rami's Data Newsletter that Apple recently introduced RDMA over Thunderbolt, and projects like Exo are making distributed inference accessible to individual developers.

That led me to a simple question:
Can I connect my MacBook Pro and Mac Mini together and effectively create a 64 GB AI machine capable of running larger models?
The answer turned out to be both Yes and No.
The “No” Part
Unfortunately, my current setup cannot take advantage of Apple's new RDMA capabilities. Apple’s RDMA over Thunderbolt requires specific hardware and software combinations. To build a true RDMA-powered Exo cluster, you currently need:
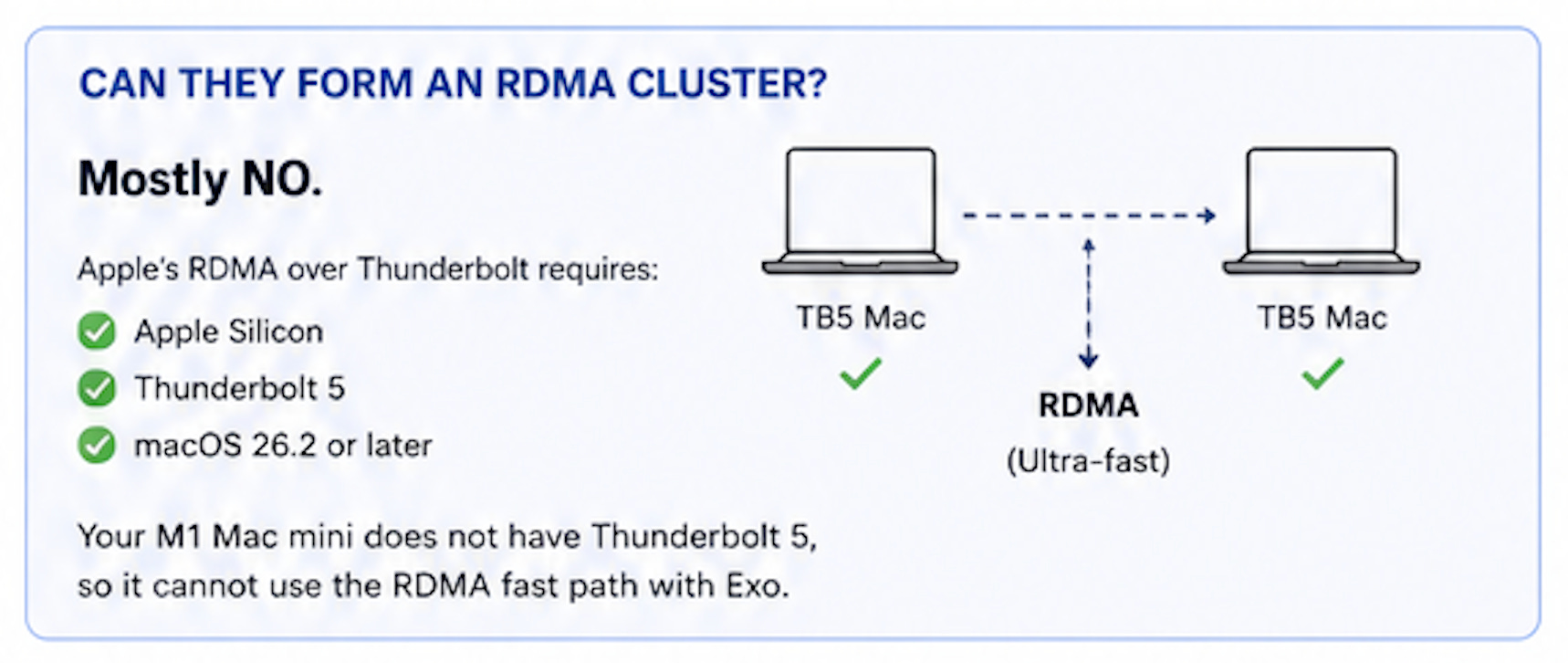
My M1 Mac Mini does not include Thunderbolt 5, which means it cannot participate in the RDMA fast path.
The "Yes" Part
Even without RDMA, Exo can still distribute inference across multiple machines. The nodes communicate over standard networking such as Wi-Fi, Ethernet and Thunderbolt Networking
This won't deliver RDMA-level performance, but it does allow experimentation with distributed inference to try out. For learning purposes, that's incredibly valuable. However, I became more interested in understanding how distributed inference actually works.
This article only scratches the surface of RDMA. If you're curious about the underlying technology and how it reduces communication overhead in distributed systems, I highly recommend exploring the resource below.
TN3205: Low-latency communication with RDMA over Thunderbolt
Memory Doesn't Get Combined
48 GB + 16 GB = 64 GB
Surely two machines connected together should give me access to 64 GB of memory? Not quite.
The operating system does not suddenly see a single machine with 64 GB of Unified Memory. Each computer still owns and manages its own memory independently.
Think of it like reading a book with multiple people. Person A reads Chapters 1-5. Person B reads Chapters 6-10. Person C reads Chapters 11-15.
Together, they can process a larger book. But nobody is holding the entire book. The same principle applies to distributed inference. Each machine stores part of the model and performs part of the computation. The model becomes larger than any single machine could host, but memory itself is not merged into one giant pool.
If the model is split across machines, how does inference actually flow from one machine to another?
How Exo Actually Executes a Prompt
Exo is a distributed inference framework that sits above the networking layer. At high level.

Let’s assume we have a model with 80 transformer layers. Instead of loading all 80 layers onto a single machine, Exo distributes them across multiple nodes.
For example: Mac A Layers = 1-40 , Mac B Layers = 41-80
Imagine I send the following prompt: Explain how a Transformer model works.
The prompt does not get processed by both machines simultaneously. Instead, it moves through the model layer by layer.
The process looks something like this ( with 4 Macs ) :
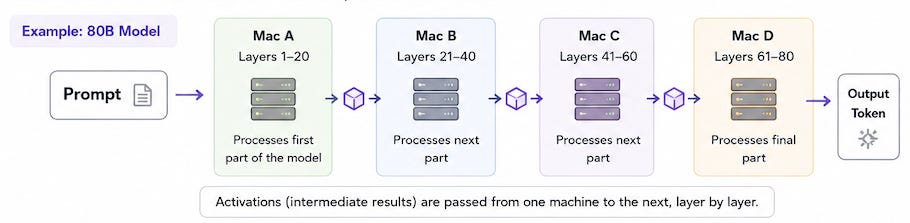
Once the first token is generated, the process repeats for every new token produced. I initially assumed that distributing the model would mean both machines independently generating responses and somehow combining them. That’s not what happens.
One machine processes its portion of the neural network and forwards the intermediate results to the next machine.
In machine learning terms, these intermediate results are often referred to as activations. Think of activations as partially completed work.
Mac A performs the first half of the thinking.
Mac B performs the second half.
Only after all layers have been evaluated can the next token be produced.
Why Network Performance Matters
Every generated token requires communication between machines.
If Machine A finishes processing its layers, Machine B cannot continue until it receives the activations. That means network latency becomes part of the inference loop.
For example.
Machine A processes its layers in
5 msMachine B processes its layers in
5 msNetwork transfer takes:
20 ms
The network is now the slowest component in the system. Even though the compute itself is fast, inference slows down because activations spend more time travelling than being processed.
Apple’s RDMA
Normally, moving data between machines involves several layers of software. Each layer introduces various overhead and all of this costs time.
Traditional Networking
Suppose Machine A wants to send data to Machine B. A simplified view looks like this:

The data passes through multiple software layers.
Along the way:
Buffers are allocated
Data is copied between memory regions
Context switches occur
Kernel networking code is executed
For normal applications, this overhead is perfectly acceptable. For distributed AI workloads generating tokens continuously, it becomes much more noticeable.
RDMA Networking
RDMA, which stands for Remote Direct Memory Access, removes much of this overhead.
Machine A Memory ⇄ RDMA ⇄ Machine B Memory
Instead of asking the operating system to move data through the entire networking stack, the network hardware can transfer data directly between memory regions. which means less copying, less CPU overhead, Lower latency and Higher throughput.
In Distributed Inference, When Mac A finishes processing its layers, it send activations to Mac B through direct memory transfer.

❌ RDMA is not shared Memory.
RDMA simply provides a much more efficient mechanism for accessing and transferring data between nodes.
KV Cache - The Hidden Memory Consumer
When we discuss model requirements, we usually focus on model size like 70B model, 120B model, 400B model, etc. However, there is another component can consume enormous amounts of memory. KV Cache.
KV Cache (Key-Value Cache)
When a prompt is processed, the model doesn’t just generate an answer and forget everything that happened.
It stores intermediate attention information from previously processed tokens so that future tokens can efficiently reference earlier parts of the conversation.
This stored attention state is called the KV Cache.
Without a KV Cache, the model would need to repeatedly recompute attention information for every previously processed token whenever a new token is generated. That would be computationally expensive and significantly slower.
Context Length
The important thing to understand is that model weights remain relatively fixed. The KV Cache grows as conversations become longer. As context length grows, the KV Cache grows as well.
8K Context = Small KV Cache
32K Context = Larger KV Cache
128K Context = Much Larger KV Cache
1M Context = Very Large KV Cache
Total Memory Usage = Model Weights + KV Cache
For short prompts, model weights usually dominate memory usage.
For long-running conversations, agent workflows, or million-token contexts, the KV Cache can become a significant portion of total memory consumption.
This is one reason distributed systems are attractive.
Distributed inference isn’t only about fitting larger models. It is also about supporting larger context windows and more simultaneous workloads.
It distribute both model layers and KV cache across multiple machines.
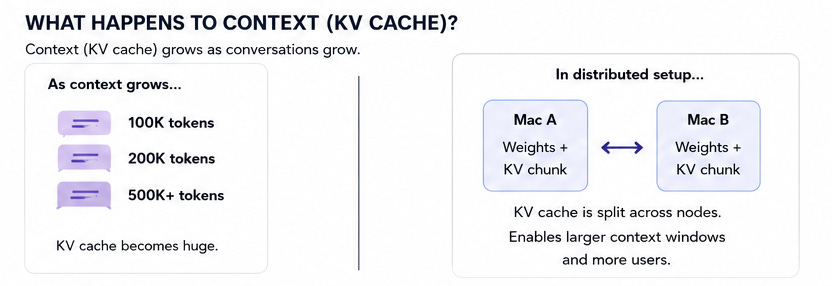
That allows workloads which would never fit comfortably on a single device.
If two Macs can become a small inference cluster today, what will local AI infrastructure look like in another two or three years?