
Mojo🔥: AI Programming Language
Bridging Python's Simplicity with Rust's Performance

Python is the go-to language for data engineering, analytics, machine learning, and AI. Why? It’s simple to write, has tons of useful libraries, and allows you to build things quickly. You, me, and all developers love that.

Python feels effortless on the surface due to its clean syntax and productivity are a big reason it’s so popular. But like an iceberg, there’s a lot hidden underneath.
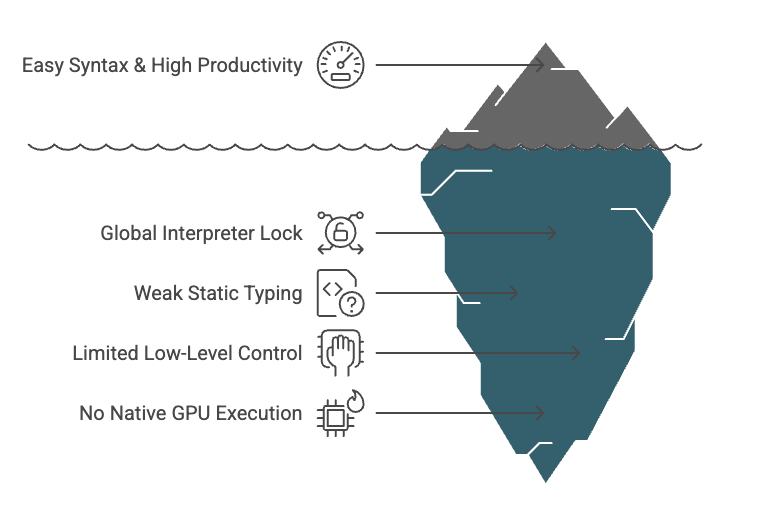
When performance challenge us, the usual reaction is to scale up with more cloud resources instead of optimizing core logic at low level.
Python struggles with things like parallel execution because of the Global Interpreter Lock (GIL). It lacks strong static typing, offers limited control over low-level operations, and doesn’t support native GPU execution. While there are just-in-time compilers like PyPy, they’re not commonly used in the AI ecosystem.
Two-Language / Two-World Problem
Especially in AI development, things often split into two phases:
Data scientists and Researchers typically use Python with libraries like NumPy, Pandas, ML Libraries or PyTorch to quickly experiment and build models. It’s great for prototyping. But when we need to train large models or to deploy those models to production and run them at scale, performance issues start to surface.
In the end, teams often have to rewrite performance-critical parts of their code in faster, lower-level languages like C++, Rust, or CUDA to run efficiently.
Take PyTorch, for example. Although it is Pythonic interface, many of its core operations and critical components are written in C++ and CUDA.
The torchscript and custom CUDA extensions are used when Python isn’t fast enough.
This gap between high-level development and low-level optimization slows teams down. To keep up with the rapid pace of AI, there's also a growing need to optimize for hardware efficiency, energy usage, and adopt AI-native hardware platforms.
Imagine Python’s Simplicity with the Speed of Rust
What if we had a language that looked like Python, but was built on a high-performance compiler infrastructure designed to optimize code at the systems level, and to run efficiently on CPUs, GPUs, and other hardware platform without needing to rewrite the code?
def main() {
print("Hello, World!, Welcome to Mojo");
}
# run mojo hello.mojoWhat is Mojo ?
Mojo is a programming language developed by Modular Inc., a company co-founded by Chris Lattner, the creator of LLVM, Clang, and the Swift programming language.
MOJO’s development began with the ambitious goal of creating a unified language that could serve the entire AI development lifecycle from initial research and prototyping to production deployment and optimization.
The language was designed to be a superset of Python, meaning that existing Python code could run on MOJO with minimal or no modifications, while new code could take advantage of MOJO's advanced performance features when needed.
If I had to define what Mojo is in one line:
“Rust running on a hardware-agnostic compiler platform” but built for Python developers.
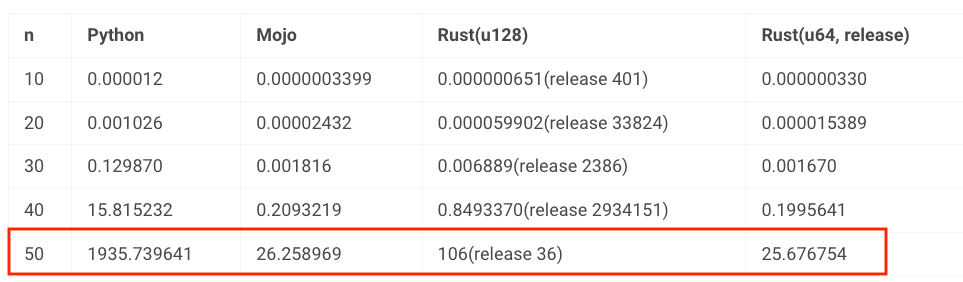
Python vs Mojo vs Rust - Speed Test
Mojo claims to be 68,000 times faster 🚀 than Python
The following chart shows the avg. time (in secs) it takes to compute the n-th fibonacci number in Python, Mojo, and Rust for different values of n:

How Mojo Works?
Architectural Foundations
Mojo is built on MLIR (Multi-Level Intermediate Representation) compiler framework, which is a key reason it stands out in accelerating Python, especially for AI workloads.
MLIR, also created by Chris Lattner during his time at Google, represents a more sophisticated approach to compiler design that allows for multiple levels of abstraction within a single framework. This architecture enables MOJO to perform optimizations that would be difficult or impossible with traditional LLVM-based compilers.
Before we go any further, it’s important to understand two foundational concepts at a high level: LLVM and MLIR.
In the coming months, I plan to publish a detailed blog post that not only explains “How LLVM works” but also explores the core principles of compiler infrastructure as I continue learning.
High-Level Overview of LLVM and MLIR
LLVM is a popular compiler infrastructure used by many programming languages. Think of it as a powerful toolkit that helps converting your high-level code (like Python) into efficient machine-level instructions that computers can run. It’s great at optimizing code for performance.

MLIR builds on LLVM but takes a step further. Instead of working with just one low-level representation of code, MLIR introduces multiple levels of intermediate representations. This multi-level design makes it easier to handle complex programming tasks, support new languages, and optimize code across different hardware platforms.
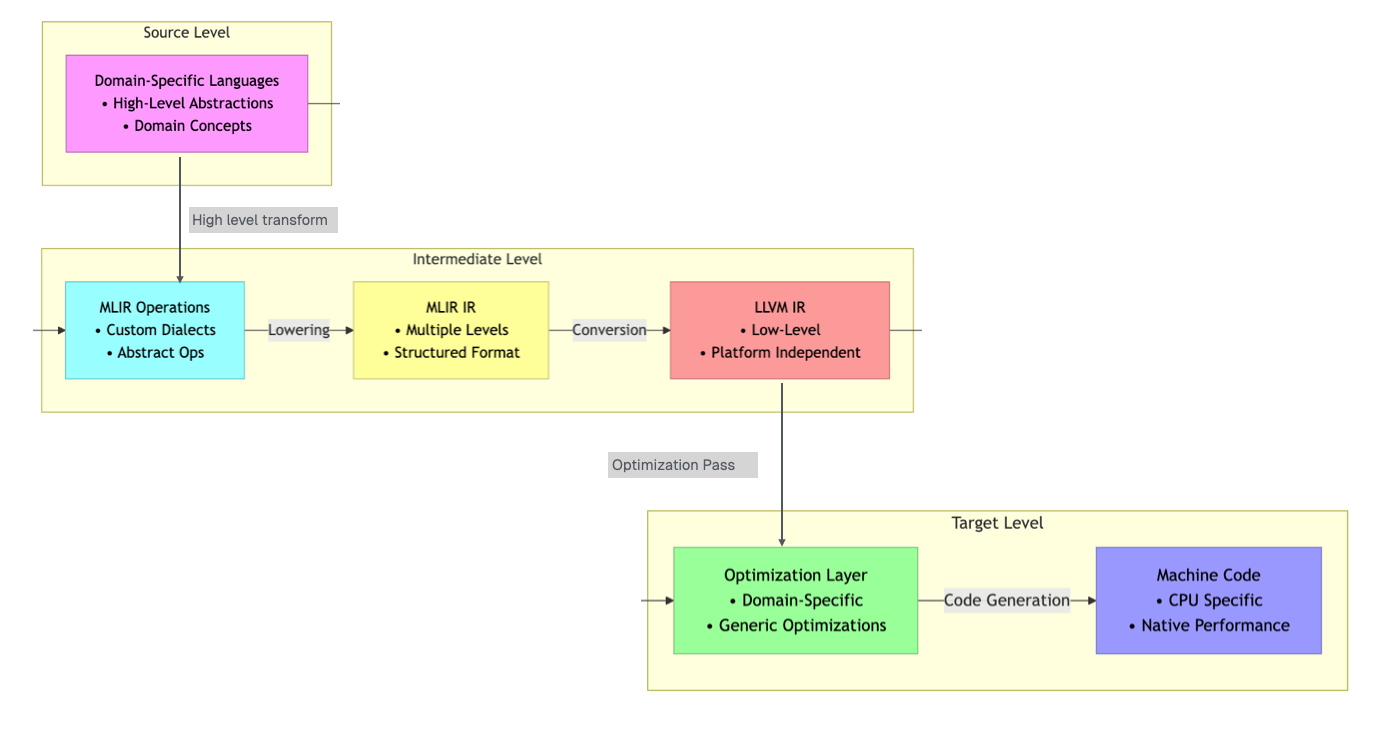
Hardware-Agnostic Approach
Mojo, built on MLIR, uses multi-level intermediate representations (IRs) to target a wide range of hardware, including:
General-purpose CPUs
Parallel and accelerated processors like GPUs, TPUs, and NPUs
Custom hardware such as FPGAs and ASICs
Emerging computing platforms like QPUs
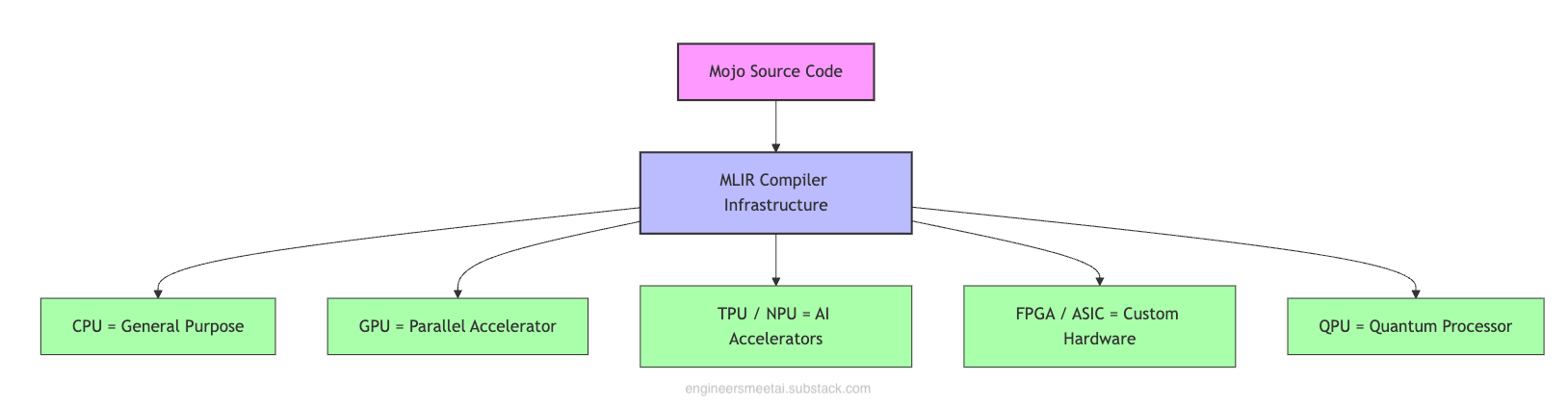
Because of MLIR, developers don’t need to learn different programming styles for each type of hardware. Unlike CUDA, which only works with NVIDIA GPUs and has its own programming language, Mojo can generate optimized code for many kinds of devices, all from the same simple code.
📌 This hardware-agnostic approach is particularly valuable as the AI hardware landscape continues to diversify. Companies like AMD, Intel, and many startups are developing specialized AI chips, and cloud providers are offering their own custom silicon (specialized semiconductor chips) for machine learning workloads. This is a significant advantage for anyone looking to avoid vendor lock-in or optimize for specific hardware configurations.
Key Features of Mojo
MOJO's design philosophy is to provide developers with the flexibility to choose their level of abstraction and performance optimization. This approach is manifested through several key features that distinguish it from both traditional Python and other high-performance programming languages.
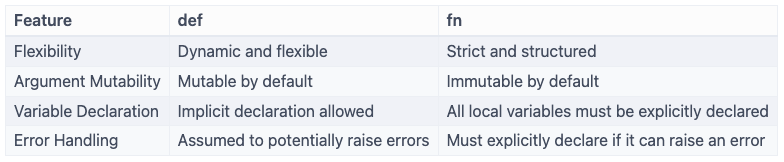
1. Dual Functions : def vs fn
Mojo supports two keywords to declare functions: def and fn.
Use def for Python-style dynamic functions, or fn when you want higher performance and stricter behavior.
2. Memory Management and the Borrow Checker
Mojo offers a streamlined approach to memory management, inspiration from Rust's ownership system to ensure memory safety without the performance cost of garbage collection.
Mojo's memory management is a “borrow checker” that analyzes code as it is compiled. This tool prevents common memory-related bugs such as using memory after it has been freed, freeing memory twice, and data races.
The goal is to provide these safety guarantees in a way that is more user-friendly for Python developers and provide clear error messages to fix memory issues quickly.
3. Automatic Vectorization and Parallelization
Mojo has built-in features to manage concurrent operations and makes parallel programming easier by providing built-in tools take full advantage of hardware.
It automatically manages threads and uses SIMD ( Single instruction, multiple data ) vectorization, so developers can concentrate on their program’s logic without worrying about low-level details.
For example, its parallelize function efficiently splits loop iterations across multiple CPU cores, which is perfect for tasks that can run in parallel on data.
Below sample code using parallelize in Mojo that squares each element of an array in parallel using all available CPU cores.

4. Struct-Based Object Model
Mojo's struct is similar to Rust’s struct, designed for speed, safety, and low-level control.
Unlike Python classes, Mojo structs are value types with a fixed layout known at compile time. This makes them highly efficient for performance-critical tasks like AI and systems programming. Yet, they retain object-oriented features like methods and operator overloading.

Mojo’s Use Cases
AI Workflow & Edge AI: Mojo optimizes tensor operations, backpropagation, and gradient descent during training. Its efficient runtime and hardware-agnostic codegen make it ideal for edge AI, real-time systems, and model serving.
Systems Programming for AI Infrastructure: Mojo isn’t just for model code. It can also power AI infrastructure like data pipelines, custom drivers, and high-performance runtimes.
References
Why Mojo - https://docs.modular.com/mojo/why-mojo
💡 Enjoyed this post? A coffee helps fuel the next one!
Useful to know and thanks.