
Synthetic Data Generation for AI
Understanding Techniques, Evaluation, Architecture, and Libraries

What is Synthetic Data ?
Data is the key for building smarter AI.
From machine learning models to large language models, all AI systems need data to learn, improve, and make decisions. But getting large, high-quality, and diverse real-world data can be difficult due to privacy concerns, high costs, and biases.
Synthetic data provides a solution. It is artificially generated to mimic the patterns and properties of real datasets, making it useful for training, testing, and protecting AI systems. Unlike real data, synthetic data can be created quickly, at scale, and without privacy concerns, helping us to improve models, handle rare cases, and reduce bias.
What This Post Covers (Part 1): Concepts, techniques, evaluation methods, architecture strategies, and libraries for synthetic data generation.
Coming Up in Part 2: I’ll dive into hands-on , showing how to generate synthetic data using popular libraries and run evaluation experiments.
Types of synthetic data
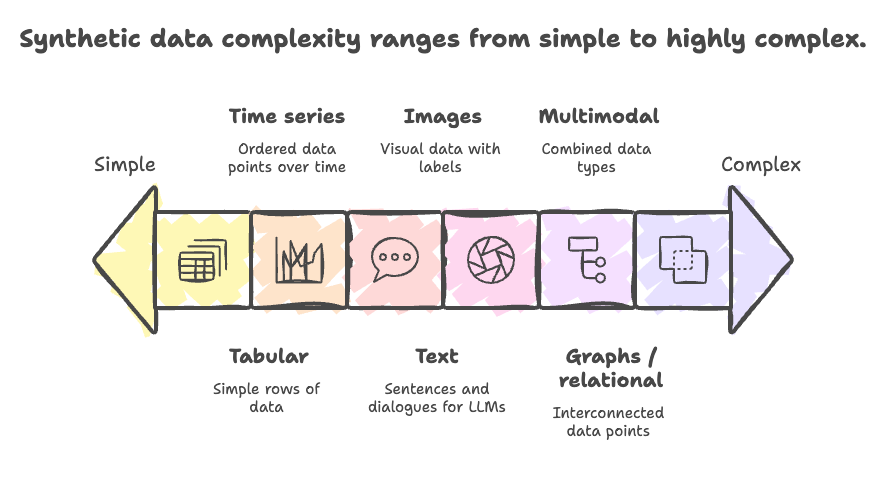
Tabular: rows with mixed categorical and continuous fields.
Text: synthetic sentences, dialogues, paraphrases, instruction/response pairs for LLMs.
Images: synthetic images from 3D renderers, GANs, or diffusion models; includes masks, bounding boxes, depth, segmentation labels.
Time series: sensor signals, medical vitals, telemetry.
Graphs / relational: synthetic networks, knowledge graphs, relational databases preserving table linkages.
Multimodal: combinations of the above (image + caption, video + transcript, LIDAR + camera).
Different generation techniques work better for different needs.
Why synthetic data matters ?
Modern AI and LLM models depends on huge amounts of data that brings several challenges. Solution like synthetic data generation can address in many ways.

1. Data Scarcity Problems
Many niche domains or emerging applications or products lack sufficient real-world data for effective model training.
Collecting and annotating data can be very expensive, time-consuming, or sometimes impossible due to the rare events or situations.
Synthetic data provides a viable alternative to bootstrap model development in such scenarios.
Example : When launching a new product, or entering a new domain, there is often no historical data available to train AI models. Synthetic data can be used to overcome this “cold start” problem, allowing initial models to be developed and deployed.
2. Data Privacy and Compliance
User centric data from healthcare, finance, or B2C, often contains private and confidential information. Using such data for AI training can result into legal and ethical concerns, including GDPR, HIPAA, and other privacy regulations.
Synthetic data, by mimicking the statistical properties of real data without containing any actual individual records, offers a privacy-safe solution.
It allows developers to train models on realistic datasets without compromising user privacy or violating data protection laws.
Example: A hospital can generate fake but realistic patient records so researchers can train models without seeing real patient names or medical history, keeping private data safe.
3. From Data Bias to AI Fairness
Real-world datasets can unintentionally create social biases to present in the data collection process. This can lead to AI models that perform unfairly across different demographic groups. Synthetic data generation ( SDG ) techniques can be designed to mitigate these biases by creating more balanced and representative datasets, thereby promoting fairness and equity in AI applications.
4. Data Variety and Edge Cases
Training robust AI models requires exposure to a wide range of scenarios, including rare events or edge cases that are difficult to capture in real datasets. Synthetic data allows for the creation of controlled and diverse datasets that can improve model robustness and generalization.
Example: If only 1% of transactions in your data are fraudulent, a fraud detection model might ignore them. You can generate more synthetic fraud cases so the model learns to detect them better.
5. Scalability and Cost-Effectiveness
Coming from Data Engineer background, I can definitely say that Collecting, cleaning, and annotating large volumes of real-world data is a manual heavy task and expensive process too. SDG can significantly reduce these costs and accelerate the data acquisition pipeline.
Once a synthetic data generation mechanism or pipeline setup done, it can produce vast quantities of data on demand, offering unparalleled scalability for training ever-larger AI models.
Controlled Experimentation and Debugging
Synthetic data provides a controlled environment for experimentation. Researchers and Engineers can generate specific scenarios to test model behavior, debug issues, and evaluate performance under various conditions. This is particularly useful for “stress-testing” models and understanding their limitations.
Example: If you are building a self-driving car model, you can generate synthetic scenarios like a pedestrian suddenly crossing the road at night, which might be too rare in your real data and checking how it behaves under tough or unusual conditions. It is a common practice in simulation-to-reality (sim2real) workflows.
⚠️ SDG only works well if it accurately captures the patterns and relationships in the real world that your model needs to learn. That’s why it’s essential to carefully evaluate whether the synthetic data improves your results.
High-level Architecture
ML Pipeline with Synthetic Data Integration

Data Preparation / ETL
Raw data from databases, APIs, or sensors is collected, cleaned, and stored in a data lake or feature store, making it ready for analysis or model training.
Synthetic Data Generation
A Synthetic Data Generation engine produces artificial data using simulations or generative models, or different techniques based on sampling of real data. This generated data are stored, validated for statistical fidelity, utility for training, and privacy, and then combined with real data for model training.
Model Training & Deployment
Models are trained on the combined dataset, evaluated for accuracy and quality, and deployed in production. Model performance feedback from deployed models can trigger the SDG engine to generate new synthetic data for underrepresented scenarios.
Feedback Loop: Continuously tracking model performance to detect drifts and use these insights to improve the synthetic data engine, creating data that addresses model gaps, covers edge cases, and reduces biases, enabling continuous system improvement.
Techniques to Generate Synthetic Data
Synthetic data generation techniques vary depending on the type of data, the desired level of fidelity and privacy, and the complexity of the underlying data distribution. These techniques can broadly be categorized into statistical methods, rule-based methods, and machine learning-based approaches.

1. Statistical Methods
Sampling from Statistical Distributions: This involves fitting statistical distributions (e.g., normal, Poisson) to the real data and then drawing new samples from these fitted distributions.
Agent-Based Modeling ( ABM ): Creating simulations of autonomous “agents” (e.g., customers ) that interact with each other and their environment based on a set of rules, generating data from their behaviors.
2. Rule-Based Methods
Generate synthetic data using explicit, deterministic rules rather than learned patterns. Examples:
Business Logic Rules: Generate data that satisfies certain constraints (e.g., invoice = sum of line items).
Scenario Rules: Create edge cases or rare events manually for testing or stress-testing systems.
3. Machine Learning and Deep Learning Methods:
Generative Adversarial Networks (GANs): GANs consist of two competing neural networks: a generator that creates synthetic data and a discriminator that tries to distinguish between real and synthetic data.
Variational Autoencoders (VAEs): VAEs are generative models that learn a compressed representation of the real data and then use this representation to generate new, similar data points.
LLMs: GPT-3, LLaMA, etc., generate text datasets for NLP tasks.
Diffusion Models: Iteratively refine random noise to create high-fidelity images or other data types.
How to Measure the Generated Data
Is it Accurate enough or Trustable to use?
Measuring the quality, accuracy, and trustworthiness of synthetic data is most important to ensure its usefulness and prevent the biases or errors into AI models. A comprehensive evaluation typically involves assessing 3 key dimensions: fidelity, utility, and privacy.

1. Fidelity ( Statistical Similarity )
Fidelity refers to how closely the synthetic data statistically resembles the real data. High fidelity means the synthetic data preserves the statistical properties, distributions, and relationships present in the original dataset.
Univariate Statistics: Compare the distribution of each individual feature (column) between real and synthetic datasets.
Examples: means, medians, standard deviations, skewness, kurtosis.
Statistical Similarity Metrics: Quantitatively measure how similar the distributions are.
Examples: Kolmogorov–Smirnov (KS) test for continuous features, Total Variation Distance, Jensen-Shannon or KL Divergence.Correlations and Dependencies: Verify that relationships between variables are preserved.
Examples: Pearson/Spearman correlations for numeric variables, contingency tables and chi-square tests for categorical variables.Histogram & Density Plots: Use visual and numerical comparisons of histograms or kernel density estimates to quickly spot distribution mismatches.
Time-Series Specific Metrics: When working with sequential or temporal data, it’s important to measure whether the synthetic data preserves temporal dependencies, seasonality, and trends.
Examples: ACF/PACF to compare temporal dependencies, DTW to measure similarity between sequences with varying speed.
2. Utility ( Usefulness )
Utility measures how well the synthetic data can be used for its intended purpose, most commonly, for training a machine learning model. This is often the most practical and important metric.
Model Performance (TSTR = Train on Synthetic, Test on Real):
Train a model (classifier, regressor, or LLM) on the synthetic data and evaluate it on a held-out real test set. Compare performance to a model trained on real data.
Classification: Accuracy, Precision, Recall, F1-score
Regression: RMSE, MAE, R²
LLM / NLP: BLEU, ROUGE, Perplexity
Transfer Learning:
Assess whether a model pre-trained on synthetic data can be fine-tuned on a smaller real dataset and still achieve competitive performance.Feature / embedding distances: For images, use Fréchet Inception Distance (FID) to compare the distribution of generated images to real images in a pretrained feature space. FID is widely used for image generators.


The image shows six experiments where faces from the CelebA dataset were gradually corrupted with different types of distortions: Top row: Gaussian noise, Gaussian blur, black rectangles and Bottom row: Swirl effect, salt-and-pepper noise, and mixing in random ImageNet images
The x-axis is disturbance level, how strong the corruption is (0 = original clean image, 3 = very corrupted). The y-axis is the FID score, how far the synthetic (or corrupted) images are from the original images in feature space.
Lower FID = more similar to real data, Higher FID = less similar (worse quality)
Feature Importance:
Compare feature importance or model coefficients between models trained on real vs. synthetic data to check if key predictive relationships are preserved.In this context, “preserved” means that the same variables have similar influence or importance in the synthetic data as they do in the real data.
Human Evaluation: Ultimately, human domain experts can provide invaluable qualitative assessment. They can identify subtle inconsistencies or unrealistic patterns that statistical measures might miss, ensuring the synthetic data makes practical sense in the real-world context it aims to represent.
3. Privacy
Privacy metrics assess whether the synthetic data not accidentally leaks any sensitive information from the original dataset.
Membership Inference Attacks
Assessing the probability that an attacker could determine whether a specific individual's data was used to train the generative model.
Attribute Disclosure Risk
Evaluate the risk of inferring sensitive attributes of individuals from the synthetic data, especially when combined with other publicly available information.
Exact Match Score: Checking for any direct copies of real records within the synthetic dataset.
Rule of thumb: prioritize task utility (TSTR, downstream performance) over raw distributional similarity. A synthetic dataset with slightly imperfect fidelity can still be valuable if it improves or speeds up model development for the real task.
Strategies to combining Real and Synthetic Data
The most effective way to leverage synthetic data is by combining it with real data, creating a hybrid approach that enhances the dataset without introducing noise or bias.
Data Augmentation: Synthetic data can be generated by transforming existing real data (e.g., rotations, flips, color changes for images; paraphrasing for text) to increase dataset size and diversity, making models more robust to variations.
Weighted Combination: When using fully synthetic data alongside real data, assigning higher weight to real data ensures the model respects ground truth, while synthetic data fills gaps or enriches underrepresented classes. Optimal weighting is determined through experimentation.
Curriculum Learning: Models can start training on synthetic-heavy data and gradually transition to more real data. This helps them learn basic patterns first and generalize better before adapting to real-world distributions.
Fine-tuning with Real Data: Pre-training on large synthetic datasets allows models to capture general features, which are then refined by fine-tuning on smaller, high-quality real datasets to match true distributions and task specifics.
Popular libraries to generate synthetic data
SDV: Synthetic Data Vault
Faker: Python package that generates fake data
gretel.ai: Synthetic data platform purpose-built for AI
fake: Rust library for generating fake data
YData Synthetic: Synthetic data generators for tabular and time-series data, including GAN-based approaches.
snorkel : generating training data with weak supervision
Further Readings / References
[Paper] arXiv 2025 - Synthetic Data Generation Using Large Language Models: Advances in Text and Code
[Paper] arXiv 2019 - Modeling Tabular Data using Conditional GAN
[Paper] arXiv 2017 - Snorkel : Rapid Training Data Creation with Weak Supervision
[Domain Specific] Synthetic Patient Population Simulator
[Domain Specific] Open-source simulator for autonomous driving research
Fantastic deep dive! Synthetic data is such a game-changer for AI, especially when real data is scarce, sensitive, or biased. Love how this post covers not just the “what” but also the “how”, techniques, evaluation metrics, architectures, and libraries. The hybrid approach of combining real and synthetic data is so practical for real-world AI projects. Definitely a must-read for engineers looking to scale models responsibly and efficiently.